【聊聊MySQL】八.MySQL-InnoDB的数据库事务的执行之REDO_LOG
一.REDO LOG
数据库最主要的特性是 持久性,即修改了数据库数据以后,无论发生什么事情,数据都不会丢失。MySQL-InnDB 就利用 REDO LOG 来满足持久性。REDO LOG 中文称为 重做日志,那也可以简洁一点叫做 REDO 日志。是数据库启动的时候,用于读取计算 BufferPool 中脏页数据的方式,这样可以避免由于其他原因导致数据库掉线但是脏页未刷新到硬盘,而导致数据丢失的尴尬局面。
二.高效且持久化的方式
由于 REDO 日志 存在的意义就是,重启数据库的时候能够重新将数据恢复回来。所以在数据库没有发生重启或者异常宕机的时候,他是没有任何意义的,甚至还多了一些开销…
所以为了减少开销,REDO 日志 应当尽量轻巧,记录一些必要的信息就可以了,比如:某个区,某个页号,的某一行,修改成xx。第二个减少开销的方式就是顺序写入硬盘,先发生的事务,REDO 日志 先被写入硬盘,后边的排队顺序追加到后面去。
三.日志格式
首先明白一点,REDO 日志 所携带的数据是 MySQL_InnoDB 在重启系统的时候,需要调用某些函数进行恢复时所需要的参数。不过,为了减少容量的开销,又做了一些事情。
3.1 装载数据的通用格式

一条重做日志,肯定会包含上面这些信息。
日志类型,在现在常用的 5.7 中,有 53 种类型,这个类型字段就很重要了,决定着程序恢复数据的方式。
MLOG_1BYTE(type = 1):表示在页面的某个偏移量写入1byte的数据的REDO 日志类型;MLOG_2BYTE(type = 2):写入2byte的数据;MLOG_4BYTE(type = 4):写入4byte的数据;MLOG_8BYTE(type = 8):写入8byte的数据;MLOG_WRITE_STRING(type = 30):写入一串数据,具体长度会放在上图中黄色的部分;

可以看到第 5 中类型在具体内容中带有一个 len 表示数据的长度,也有点类似于我们做 RPC 的时候为了粘包写的长度。那我们业务中每次更新都会更新很多东西,可以说基本都是使用第 5 种日志类型了。
而 偏移量在上面所有类型的日志中都有。
3.2 插入数据时日志格式
OK,现在我们来了解下日志存储哪些东西。
我们日常插入,比如说 INSERT INTO student values(1, 'Weidan', 'BOY') 这条插入语句,看似只需要插入一条数据即可,但是还记得吗,之前说过的页分裂问题呀,还有调整页参数信息的问题:
如果还记得这些内容的话,跳过我引用的内容
页头信息主要包含以下几个部分:
名称 大小(字节数) 主要作用 FILE_PAGE_SPACE_OR_CHKSUM 4 4.0.14之前存放在哪个表空间
后面的版本存储checksum值FILE_PAGE_OFFSET 4 表空间中页的页号 FILE_PAGE_PREV 4 上一页 FILE_PAGE_NEXT 4 下一页 FILE_PAGE_LSN 8 最后修改的日志序号 Log Swquence NumberFILE_PAGE_TYPE 2 页的类型: 在后面给出FILE_PAGE_FILE_FLUSH_LSN 8 代表文件被更新到该指定的LSN值 FILE_PAGE_ARCH_LOG_NO_OR_SPACE_ID 4 属于哪个表空间
如果说
FileHeader是用来记录文件的信息,那PageHeader就是用来记录当前数据页的状态信息了。同样也是一堆
Key:
名称 大小(字节) 主要作用 PAGE_N_DIR_SLOTS 2 Page Directory 页目录中的槽数 PAGE_HEAP_TOP 2 堆中第一个记录的指针 PAGE_N_HEAP 2 堆中记录数 PAGE_FREE 2 空闲列表首指针 PAGE_GARBAGE 2 已删除的字节数 PAGE_LAST_INSERT 2 最后插入的位置 PAGE_DIRECTION 2 插入数据的方向 PAGE_N_DIRECTION 2 一个方向连续插入记录的数量 PAGE_N_RECS 2 该页记录数 PAGE_MAX_TRX_ID 8 当前页最大事务ID PAGE_LEVEL 2 索引树中的位置 0x00代表叶节点 PAGE_INDEX_ID 8 当前页属于哪个索引的id PAGE_BTR_SEG_LEAF 10 叶子节点中文件段首指针位置(B+的Root页中定义) PAGE_BTR_SEG_TOP 10 非叶子节点中文件段首指针位置(B+的Root页中定义)
Infimum记录比当前页最小主键还要小的“值”,Supremum记录比当前页最大值还要大的“值”。值我打了双引号,并不是说他就是一个值,而是一个规定:一个页中,Infimum 记录的下一条记录就是本页中最小的记录,而本页中最大的记录的下一条记录就是 Supremum 记录 。 (这里的下一条
next_record的字段是Row Format规定的头,后面讲行信息的头部消息的时候我会重新说一下这句的)
页分裂:

好了,所以说,插入一条数据的时候需要调整的东西特别多,而且这些地方的调整都需要生成 REDO 日志。
但是这些需要修改的地方特别零散,他并不是聚集在一起的

上图黄色的地方就是被修改的数据。
那现在有两种解决方案,一种是修改多少个地方就记录多少条日志,这样就需要 8 条 REDO 日志。
那如果说将第一个修改的地方,和最后一个修改的地方,所有数据都进行记录的话,像上面那张图,最后一个因为拉的很远,中间那些没有修改的数据就都需要放到 REDO 日志 上去,那么这样又感觉不优雅(讲真我以前我还真的这么干过用户编辑信息)。
两种方案,一个太多,一个太大。所以就诞生了其他的 REDO 日志 类型:
MLOG_COMP_REC_INSERT(type = 38):表示插入一条使用紧凑行格式的记录时的日志类型;MLOG_COMP_PAGE_CREATE(type = 58):表示创建一个存储紧凑行格式记录的页面的日志类型;MLOG_COMP_REC_DELETE(type = 42):表示删除一条紧凑型行格式的数据的日志类型;- ……
太多了,不过看第三个表示 REC 和 PAGE 分别表示对应的行还是页做操作,第四个就是增删查改了。
但是有个比较特殊,那就是 批量删除 了:
MLOG_COMP_LIST_START_DELETE(type = 44)和 MLOG_COMP_LIST_END_DELETE (type = 43)表示批量删除的时候,开始删除跟结束删除的两条范围记录。
3.2 REDO 日志内容
而一个 REDO 日志 包含了两个层面的东西:

而逻辑层面的东西,并不是说在重启的时候直接回复到数据文件中,而是需要经过一系列的计算,然后再得出最后结果写入数据文件,类似于 Java 写 方法 的时候需要用到的一些参数信息。而上一节中的类型,指的是参数的不同,InnoDB 恰好可以根据这些参数计算出来对应的 PAGE_N_DIR_SLOTS PAGE_N_HEAP 等等信息,然后恢复到数据库中。
四.重做LOG的’事务’
重做LOG 的’事务’ 也成为 Mini-Transaction,因为我们知道系统每次写一页是 4kb,磁盘一次 IO 是 512 byte。那如果 重做LOG 在写入硬盘的时候,写少了点东西,势必导致这部分的日志被破坏不可用了,所以 InnoDB 规定,某些修改数据页的 重做LOG 必须一起被写入硬盘,这部分的 重做LOG 才算真的有效。
我们上面已经知道,一条修改语句或者新增语句将会更多多个地方,就真的可能出现了多个 重做LOG,更何况我们一般开事务也不会无聊到只运行一条增删改语句,所以一个事务下来,就会出现很多条 重做LOG,那从上面又知道,因为各个硬件写入的速率不同,所以需要有些 Mini-Transaction:
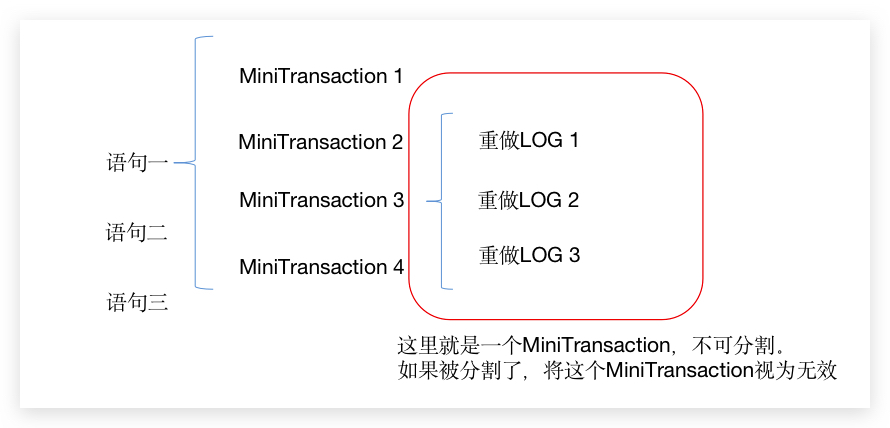
以下这些常见情况,必须视为一个不可分割的 Mini-Transaction:
- 没有指定
主键的情况下,全局更新Max Row ID时候产生的重做LOG; - 向聚簇索引的
B+树插入一条记录产生的重做LOG; - 向二级索引对应的
B+树插入一条记录的日志; - ……
五.重做LOG缓冲区
日志已经生成,这时候需要考虑的就是怎么落地的问题了,所以就有了 日志缓冲区,区 放的是 重做LOG数据页(跟数据的数据页不同):

HEADER 和 FOOTER 并不打算细说了,主要就是为了校验,以及管理 BODY 中的内容。所以我们主要来说说 BODY。
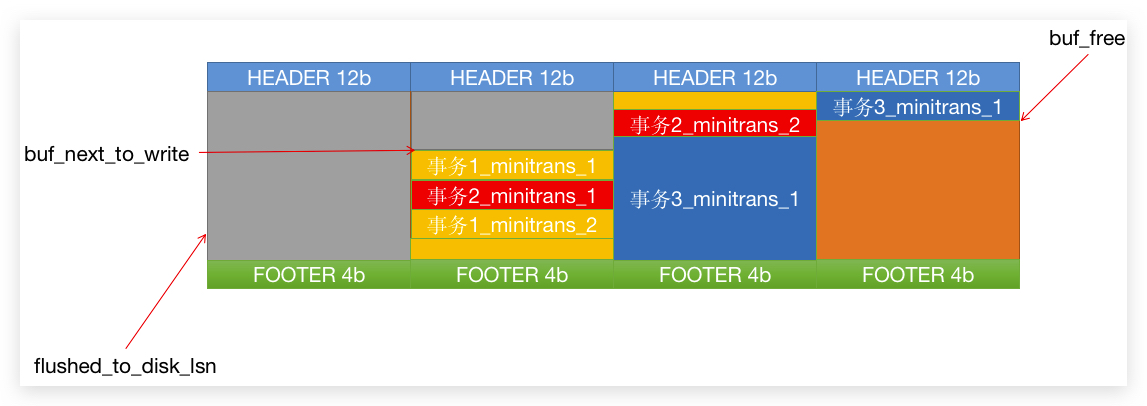
那么 重做LOG 不可能是串行写入的,要不然速度就上不去了,所以运行时 日志缓冲区 就看起来可能是这样的:
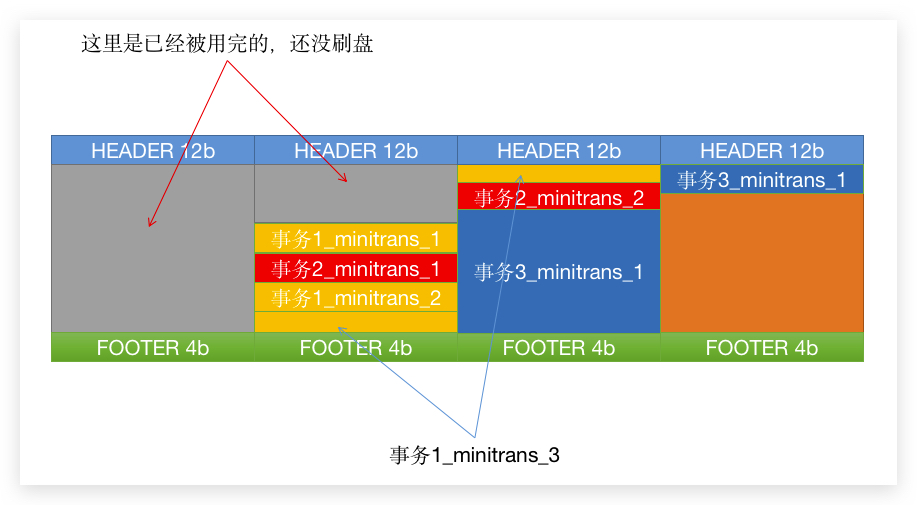
如图,事务1 和 事务2 的 MiniTransaction 是交叉运行的,而 事务3 更新的内容比较多,所以会占用多个 缓冲页,有些甚至更大,会占用多个 缓冲页。
六.触发重做LOG刷盘
上面那张图引出另外一个问题,已经写入 缓冲区 的 重做LOG 需要怎么落地,如果不落地,那已关机,内存中的 缓冲区 一旦清空,重做LOG 就没有意义了。所以就需要有个机制来刷新这些 重做LOG数据 到硬盘中,那么刷盘的触发情况分为以下几种情况:
- 空间不足,占用配置的
innodb_log_buffer_size一半左右 的时候,就会触发刷盘; - 事务提交时刷盘,只有刷盘了,才能保证持久性;
- 后台线程,循环着做这件事情,这个前面已经有说过了;
- 关闭服务器;
- …
七.重做LOG刷到哪些文件里
既然要刷盘,那就肯定有对应的文件来接收这些数据,可以通过 SHOW VARIABLES LIKE '%datadir%' 来查看是哪些文件,默认是有 ib_logfile0 和 ib_logfile1。那如果我们需要调整,调大或者调小就使用下面的参数进行调整:
innodb_log_group_home_dir:存储日志的目录;innodb_log_file_size:每个文件的大小,感觉大小这个度需要把握好,太小会导致很多重做LOG不完整,太大又不利于防灾;innodb_log_files_in_group:分割日志的个数,默认是2个;
那 InnoDB 在写 重做LOG 的时候就从编号 0 开始,写到最后一个。如果到了最后一个并且已经用完了所有空间了,那就重新从 0 开始,依次类推循环的写入硬盘。
循环从头开始写 重做LOG 的时候,那必须会碰到 前面的重做LOG 被覆盖的问题,那如何判断前面的 重做LOG 是否还有用,就是需要判断 BufferPool 中的 脏页 是否已经被刷新到硬盘了,如果已经刷新成功,那么这部分的 重做LOG 肯定是没有用的,可以放心的覆盖。这就回到了我们的初衷:持久化且高效的保存数据。
那如何判断咧,需要结合之前我们在 BufferPool 中说到的 flush链表 了。
八.重做LOG缓冲页与日志文件的关系
8.1 重做日志文件的格式
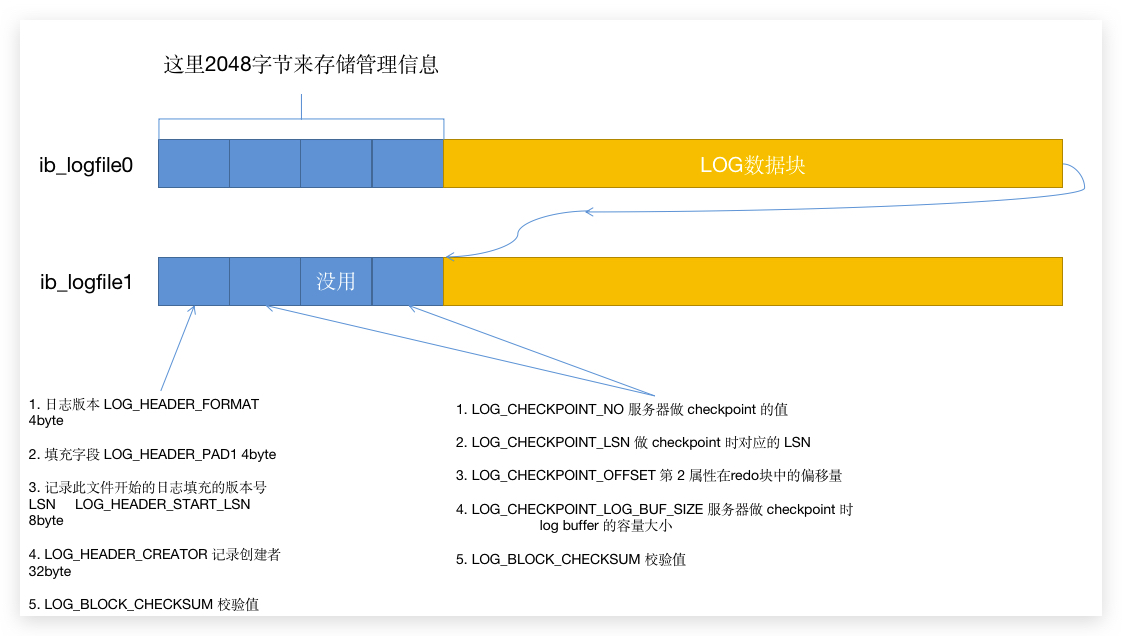
上面 第一个管理单元 和 第二四管理单元 里面涉及到的 LSN 和 CheckPoint 是重点。
8.2 LSN - Log Swquence Number
LSN 是一个日志的序列号,这个值从开始有 REDO 开始,将会不停的自增,可以理解为数据表的主键一样,插入一条新的数据的 自增ID 变化情况。InnoDB 会有一个全局变量,专门用于记录这个值变化到哪个数据点,不过他不是从 0 开始而是从 8704 开始,也就是规定一条 重做LOG 都没有的情况下,这个 全局变量 的值就是 8704。
而 LSN 的增长,是会加上 重做LOG页 的头部和尾部的,就是说当一个 MiniTransaction 跨越几个区的时候,那这个值里面就包含了覆盖到的 HEADER 和 FOOTER 值。 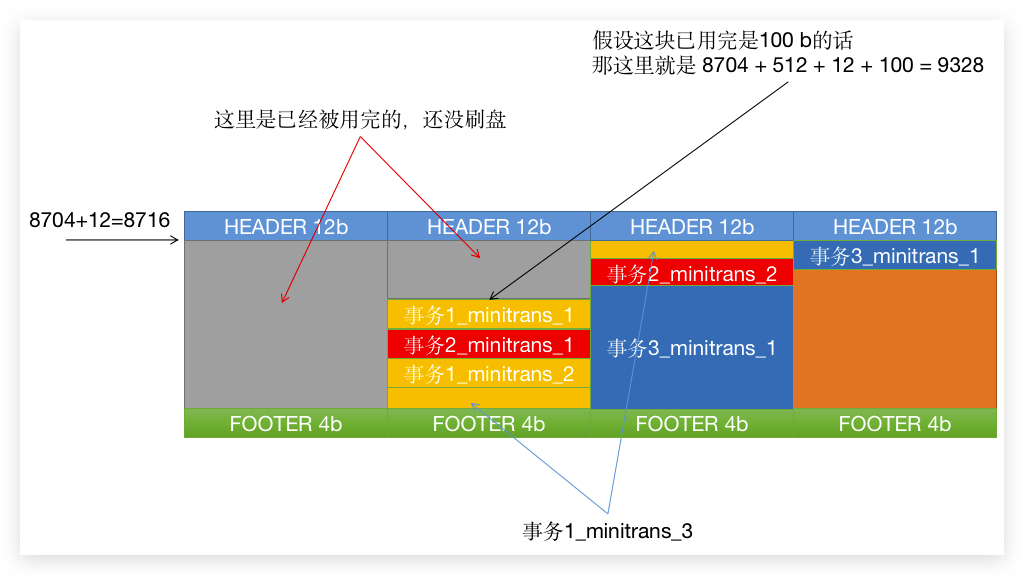
8.4 日志缓冲数据刷盘
由于需要刷盘,并且记录哪些数据已经被刷新到硬盘了,这样才能够释放内存空间让后面的 重做LOG 来用。所以上面提到的 LSN 就开始有用处了。
这时候,InnoDB 中又出现了几个全局变量(可以理解为指针):
buf_next_to_write:此指针之前的数据表示已经准备刷盘的日志数据,这部分的日志数据已经可以被复用的;flushed_to_disk_lsn:系统已经返回刷新成功的LSN的值;buf_free:此指针之后的内存空间表示是空闲的,如果有新的日志要进来,就需要追加到后面的内存中去,这个值其实就是跟上面提到的LSN一样的值。
那 buf_next_to_write 到 buf_free 中间的数据就是已经存在于 内存中的,但是 还没有提交刷入硬盘的请求给系统的数据。
刷新硬盘:我们需要将文件写入硬盘的时候,其实是提交请求给系统,系统将数据放入数据缓冲区,在某个时刻被刷盘,只有调用了
fsync函数之后,数据才是真正的进入硬盘。所以这时候需要两个变量来弄清楚哪些数据已经提交给系统,哪些数据已经完完整整落在硬盘上的,就分别对应buf_next_to_write和flushed_to_disk_lsn两个变量参数。
那我们就可以知道,刚开机的时候,LSN 的值和上面三个全局变量其实应该是相等的,随着系统的运行,SQL 不断的请求,这时候 buf_free 一定会跑得比别的参数快,然后随着写入硬盘的请求逐步完成,当四个值都相等的时候,就表示所有的日志已经刷入硬盘了。
8.5 flush链表和LSN
flush链表:
flush链表主要是用来管理BufferPool中已经被修改的数据页,因为此时内存中的数据页已经发生修改,和硬盘上原有的数据页不同,所以就需要在某个时刻由后台线程刷新到硬盘上去。但是,这个时候总不可能去循环所有数据页,然后判断是不是脏页吧,所以又有一条链表产生,就是
flush链表。
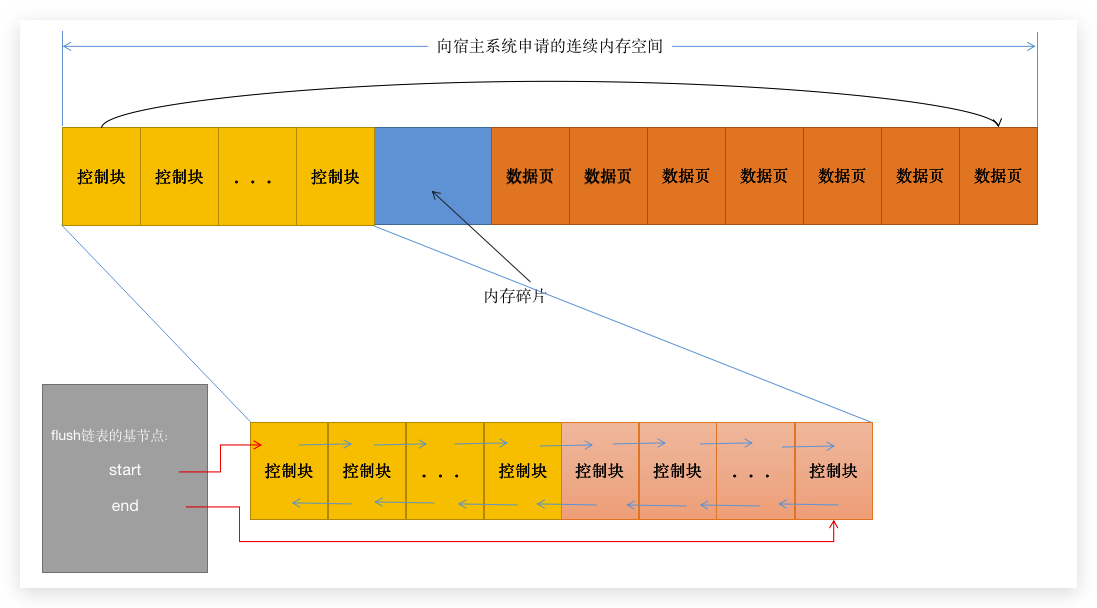
我们在对数据进行修改的时候,一直处于 重做LOG缓冲区 的视觉,现在需要将视觉切换到 BufferPool 中去,BufferPool 还有个东西,叫做 flush链表,为了回忆我已经将上次写的东西放在了上面。
那我们需要结合 MiniTransaction 来说,每个控制块里面有两个属性,一个叫做 oldest_modification 一个叫做 newest_modification。oldest_modification 会记录在开始做修改时 LSN 的值,修改完成后,newest_modification 记录修改后的 LSN 的值。
那 flush链表 会发生哪些变化,我直接画个动态图来说吧:

最后的状态:
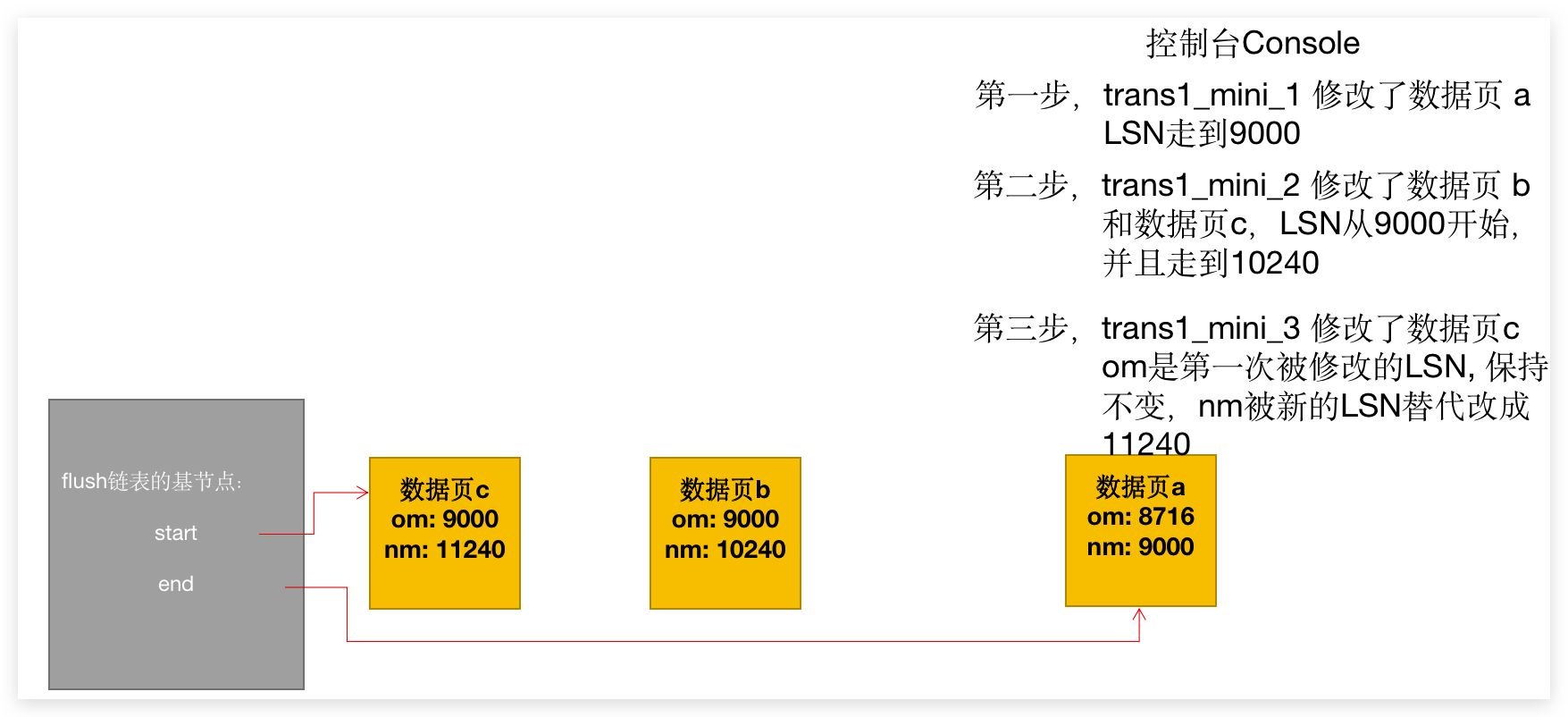
归纳几个特点:
- 最新被修改的数据页,总是会被移动到链表的开始;
- 链表的尾部是比较早些时候发生修改的数据页;
- 如果一个数据页发生过修改已经存在于
flush链表中的话,如果又有新的修改,om保持不变,nm会被修改成新的LSN值。
8.6 Checkpoint
在 第七节 的时候说过:
那
InnoDB在写重做LOG的时候就从编号0开始,写到最后一个。如果到了最后一个并且已经用完了所有空间了,那就重新从0开始,依次类推循环的写入硬盘。
所以我们的两个日志文件 ib_logfile0 和 ib_logfile1 ,ib_logfile1 在写到结尾的时候,会重新回到 ib_logfile0 开始写,那么 Checkpoint 的提出就是为了解决在回去写 ib_logfile0 的时候是否可以覆盖前面的日志的问题。
结合上面说的 flush链表,那就可以说了,InnoDB 只需要判断前面的 重做LOG 对应的数据页是否存在 flush链表,如果不存在,则表示这些数据页已经顺利写到数据页中去,也就表明前面的 重做LOG 已经可以覆盖掉了。
所以,InnoDB 又用了一个全局的变量 checkpoint_lsn 来表示数据页刷新到哪个 LSN 了,而这个值每次在脏页被写入硬盘的时候就会被修改成当前脏页的 newest_modification。也是下一个脏页的 oldest_modification。那么 重做LOG 刚开始的日志 LSN 如果小于这个 checkpoint_lsn 的话,表示这些日志已经没用了,可以被覆盖掉。而每进行一次 checkpoint 后,checkpoint_lsn 的值就会被写入日志实体文件的管理信息里面,就是下面蓝色部分:
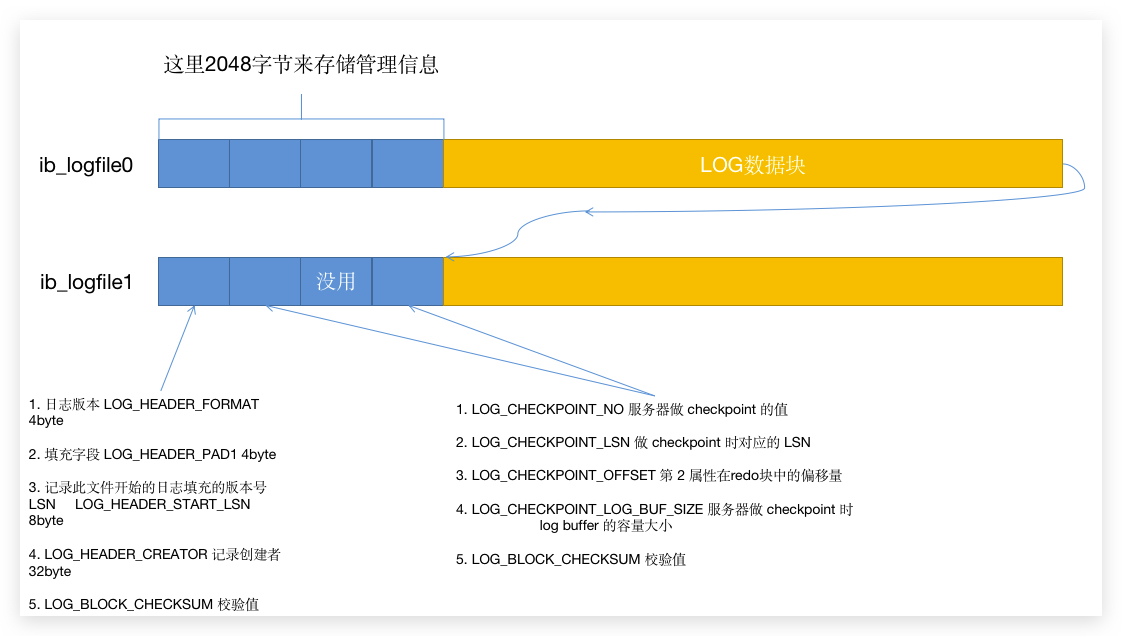
那这时候我们就可以来说说管理信息中两个 Checkpoint 块信息的事情了。
LOG_CHECKPOINT_NO 是服务器做 Checkpoint 的次数,这个变量有个全局变量,每做一次,此变量就会自增加1,然后被一起写入到这个管理信息块中去。而 LOG_CHECKPOINT_OFFSET 则对应的日志数据的偏移量。那这个偏移量前面的数据就是可以丢弃的。而放入那个 Checkpoint块 中,InnoDB 会判断 LOG_CHECKPOINT_NO,如果这个数是 偶数 就写入 第一个 块中,如果是 奇数 就写入 第二个 块中。
九.崩溃重做数据页
第八节 说了这么多记录重做的事情,那如果系统发生崩溃需要重做,这时候 重做LOG 就发挥用处了。
那硬盘中的 重做文件 的 头信息 将起到计算从哪里开始恢复的作用:
- 先读取两个文件的所有管理块信息;
- 从所有管理块信息中的两个
Checkpoint信息中,确定哪个信息的checkpoint_no比较大,则表示上次checkpoint做到哪个信息中,这时候就可以顺势拿出checkpoint_log_offset之后的日志数据了,那这一步就可以确定恢复的日志起点; - 确定哪个
重做LOG数据页的BODY没有被写满,则这个地方就是最后需要恢复的地方了; - 然后先排序所有的
重做LOG数据,然后将相同表空间ID和页号的重做数据放在一起(Hash的方式,可以想象成Map<TableIdAndPage, List<Log>>的结构); - 由于后台线程在不停的刷新脏页,可能发生数据页已经刷盘但是还没来得及写
checkpoint的情况,所以现在所有日志并不是都需要重做一次,如果出现数据页结构中的File Header的FIL_PAGE_LSN值大于checkpoint_lsn的话,说明数据已经刷入硬盘了,就不需要再重做。否则,将重做LOG中的修改某某地方为某个值重新按顺序执行一遍,就可以恢复到奔溃前的数据了。
十.配置重做日志的级别
重做日志是为了 持久化,那总有一些业务要求的持久化没那么强烈。
如果不需要在每次提交的时候就刷新到硬盘的话,可以修改 innodb_flush_log_at_trx_commit 的值:
0:表示提交的时候不立即刷新日志,交给后台系统循环去刷新;1:默认值,表示每次提交需要同步到硬盘;2:表示提交加入系统缓冲区,交给系统去刷新,这种情况下如果数据库挂了系统没挂的话,那日志一般不会丢失。