【聊聊MySQL】十.MySQL-InnoDB的数据库事务的执行之MVCC
一.事务的隔离
刚开始我们说了事务的四个特性:原子性 一致性 隔离性 持久性。
我们简单的分一下类: redo log 可以保证事务的 原子性 和 持久性,undo log 可以保证事务的 一致性,那么剩下的 隔离性 就由我们现在要说的 MVCC 来保证了。
那么隔离性是个啥,之前说过了,也就是可能出现 脏写 脏读 幻读 不可重复读 等等这些状况。
简单回顾下:
- 脏写:A事务提交的数据是B事务
UPDATE的值 ,这个无论如何都不允许; - 脏读:A事务中读取到了B事务中
UPDATE的值(B事务未提交); - 不可重复读:A事务中两次读取,第二次读取到B事务已经提交的
UPDATE的值(注意跟脏读的区别); - 幻读:A事务两次读取,第二次读取到B事务中提交的
INSERT的值,但是如果A事务两次读取,第二次读不到B事务DELETE的数据,不属于幻读,幻读强调第二次读取的时候,多了数据;
二.MVCC
MVCC 表示 Multi-Version Concurrency Control,多版本并发控制。也就是说在多个事务执行的情况下,可以控制事务读取到的数据版本的问题。
而 MVCC 的关键就在于之前 undo log 所说的 版本链 上。
2.1 版本链
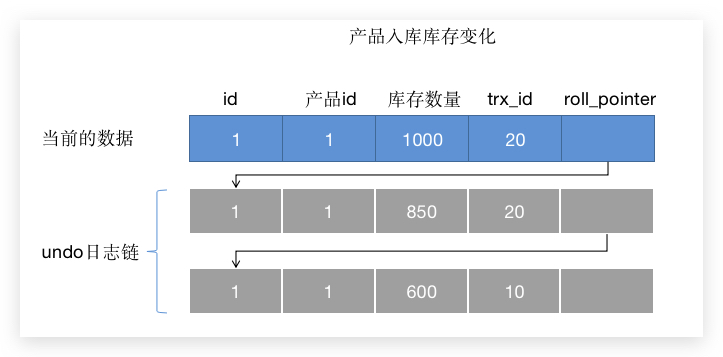
之前说过这个图,第一次插入的时候,生成了第一条 undo_insert_rec,而对这个数据行做删除的时候,就会把数据行中的 roll_pointer 打断,连接到删除的 undo log 上,而 undo log 中的 old_roll_pointer 又指向了前一个插入的 undo log 中。
由于上面太乱我重新画张图:
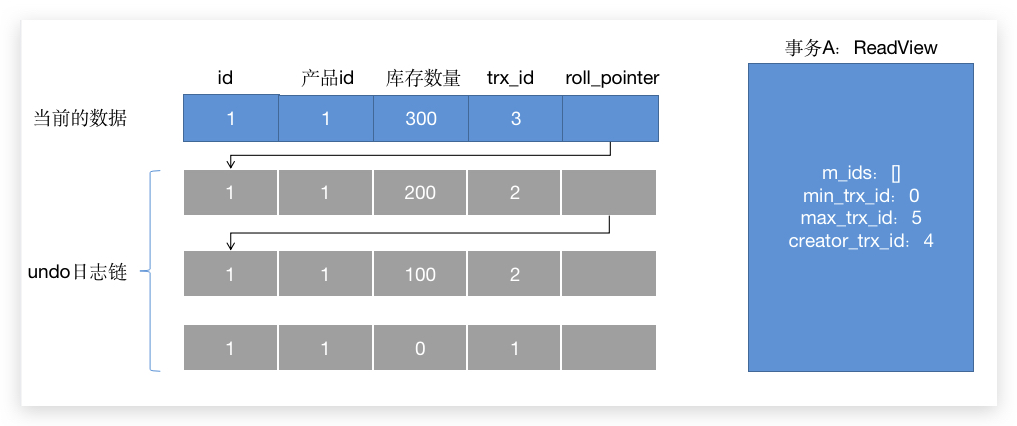
OK,这是一个产品入库的过程。两个事务对这个条数据发生了更新,假设事务A和事务B(事务A的 trx_id=20,事务B的 trx_id=10)。事务B修改库存为 600,而事务A做了两次修改,第一次是 850 第二次是 1000。所以上图中,比较低层的是旧的数据,比较高层的是新的数据。这个列表串起来就是一条数据的 版本链。
有了这个版本链还不够,还需要一个 ReadView 来辅助查询。
2.2 ReadView
这个名字也很好理解了:读取视图。他发生在 SELECT 的时候,每次 SELECT 都会从数据表中生成一个 ReadView。
ReadView 有几个非常重要的属性:
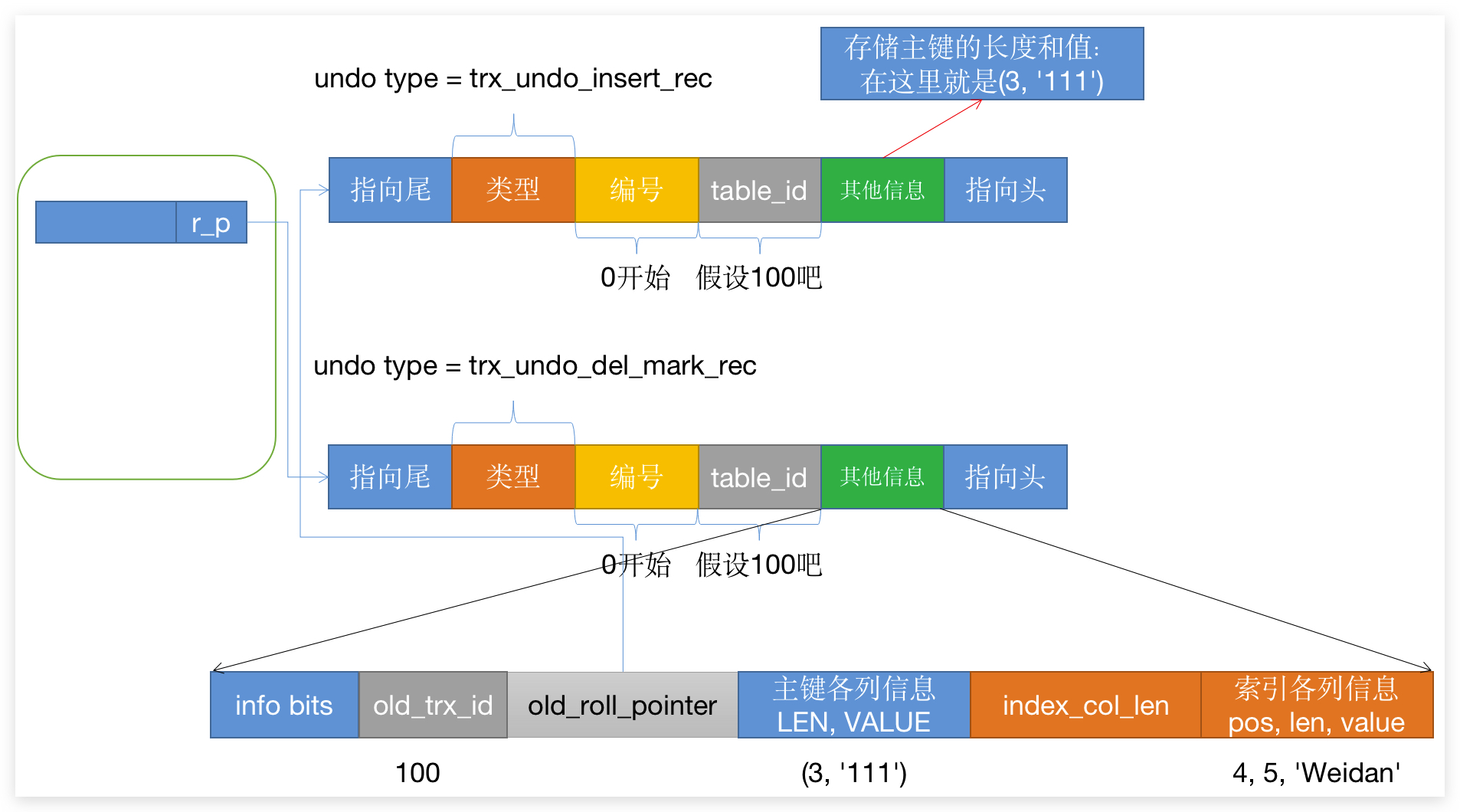
m_ids:生成时活跃的读写事务trx_id列表;min_trx_id:上面m_ids最小的值;max_trx_id:生成时应该分配给下一个事务的trx_id值;creator_trx_id:当前事务的trx_id值;
那我们要查询上面的某条记录的时候,就需要根据 ReadView 中的那些值与 undo log 或者 数据行 中的 trx_id 比较,来拿到满足条件的最新一条的记录,就是当前事务可以访问到的数据。
怎么判断:
- 如果
数据行的trx_id与当前事务id相等,也就是与creator_trx_id说明这条数据在当前事务发生更改,所以当前事务可以访问; - 如果
数据行的trx_id小于min_trx_id说明这个数据的改动在这个事务之前已经提交,所以可以被访问到; - 如果
数据行的trx_id大于或等于max_trx_id,说明该版本在这个事务之后发生的更改,所以这个版本不可见,继续遍历下一个版本; - 如果
数据行的trx_id介于min_trx_id和max_trx_id之间,则需要判断事务是否存在于m_ids中:- 如果存在,说明创建的时候事务还在活跃中,数据版本不可见;
- 如果不存在,说明已经提交了,则数据版本可见
然后我们知道,数据库有不同的隔离级别,MySQL 有 READ UNCOMMITTED READ COMMITTED REPEATABLE READ SERIALIZABLE:
READ UNCOMMITTED:所有遇到的问题情况都允许,所以不用考虑;
SERIALIZABLE:所有查询写入均需要串行执行,所以也不用考虑。
那么主要就是 READ COMMITTED REPEATABLE READ 这两个隔离级别通过不同的方式来使用 ReadView。READ COMMITTED 是在每一次 SELECT 的时候生成 ReadView,而 REPEATABLE READ 则是在每次事务开始的时候生成的。
2.3 查询示例
来举个栗子吧,我们假设当前的隔离级别是 READ COMMITTED:
| 步骤 | 事务A(trx=1) | 事务B(trx=2) | 事务C(trx=3) | 结果 |
|---|---|---|---|---|
| 1 | BEGIN;INSERT INTO(1, 1, 0);COMMIT; |
|||
| 2 | BEGIN; |
BEGIN; |
||
| 3 | BEGIN; trx=4 |
UPDATE quantity = 100 |
||
| 4 | UPDATE xxx(为了分配到trx_id) |
UPDATE quantity = 200 |
UPDATE xxx(为了分配到trx_id) |
|
| 5 | SELECT quantity |
UPDATE quantity = 300 |
0 |
|
| 6 | COMMIT |
|||
| 7 | SELECT quantity |
200 |
||
| 8 | COMMIT |
|||
| 9 | SELECT quantity |
300 |
分步骤来说:
- 第
1步,事务A开启一个事务插入一条数据,这时候数据行的 trx_id = 1; - 第
2步,事务B和事务C分别开启事务,准备对这条数据蠢蠢欲动; - 第
3步:事务A又开启一个事务,分配了trx_id = 4;- 同时
事务B更新了数量100;
- 第
4步:事务B又更新了数量200;
- 第
5步:事务C也更新了数量300,事务A查询了数量,这时候 结果是0; - 第
6步:事务B进行了提交; - 第
7步:事务A查询了数量,结果是200; - 第
8步:事务C提交; - 第
9步:事务A查询数量,结果是300。
那接下来讨论的就是上面的步骤中,三次查询 的结果:
第一次,发生在第 5 步:
事务A 查询的时候创建了 ReadView,这时候根据上面的判断,迭代目前的数据版本:
我们看看第一个结果 0,发生在 第 5 步:
第一条数据:
trx_id = 3,不等于ReadView的creator_trx_id,所以这个条件不满足,下一个判断,- 明显当前
trx_id大于ReadView的min_trx_id,所以继续下一个判断, - 当前
trx_id小于max_trx_id,所以这个判断不执行; - 当前
trx_id存在于m_ids中,说明开启事务的时候,这个版本还在其他事务范围之内,所以这条不能被访问;
第二条数据:
…【与上面一样】
第三条数据:
…【与上面一样】
第四条数据
trx_id = 1明显小于min_trx_id,所以这条数据可以被事务A访问,返回数据0。
接下来看看第二个结果 200,发生在 第 7 步,这时候,事务B 已经提交了,所以 ReadView 的情况就是下面这种:
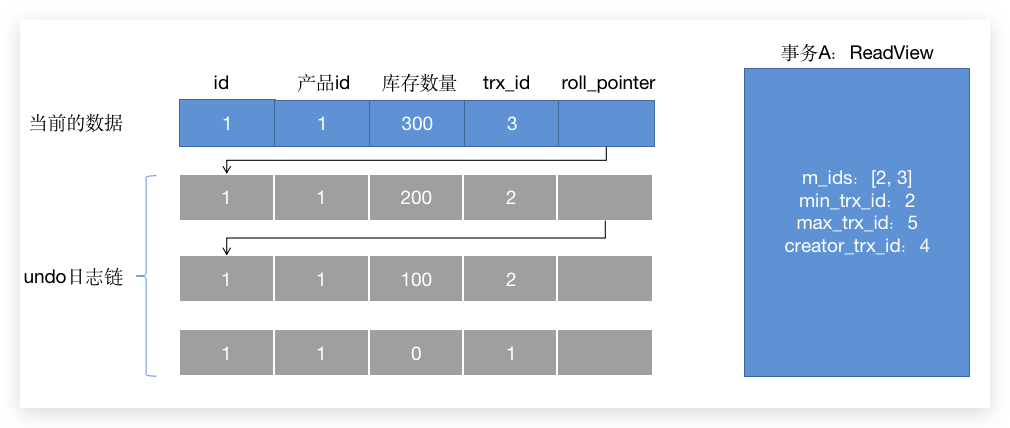
- 第一条数据:
trx_id = 3,不等于ReadView的creator_trx_id,所以这个条件不满足,下一个判断,- 明显当前
trx_id大于ReadView的min_trx_id,所以继续下一个判断, - 当前
trx_id小于max_trx_id,所以这个判断不执行; - 当前
trx_id存在于m_ids中,说明开启事务的时候,这个版本还在其他事务范围之内,所以这条不能被访问;
- 第二条数据:
trx_id = 2,不等于ReadView的creator_trx_id,所以这个条件不满足,下一个判断,- 当前
trx_id小于ReadView的min_trx_id,所以返回这条数据,所以查询到的quantity = 200
然后,随着 事务C 也提交了,这时候系统中没有正在运行的事务:
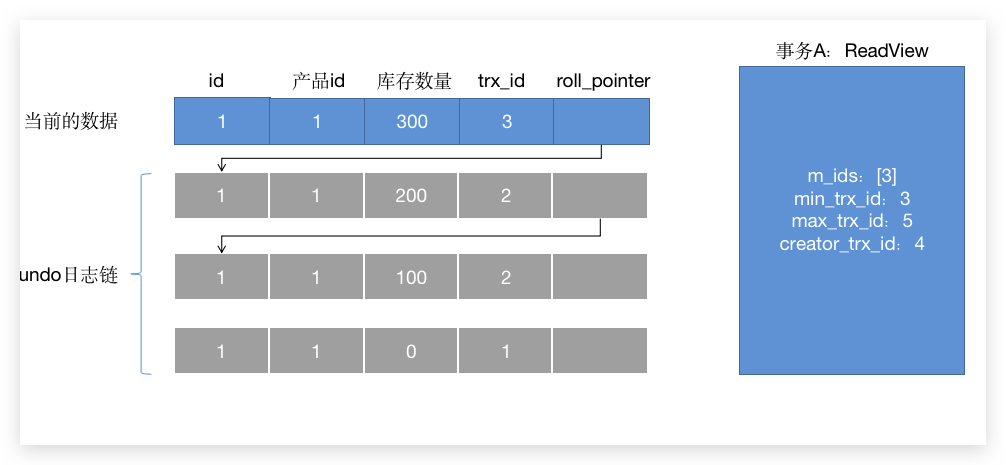
那么第一条数据做第一个判断的时候,发现当前已经没有事务在运行了,所以这条记录是这个事务之前提交的,就会被访问到,直接返回 300。
所以需要注意的是: READ COMMITTED 每次查询都会生成一个新的 ReadView 所以就发生了 不可重复读。
那如果是 REPEATABLE READ ,他会在查询的时候就根据目前事务的情况创建 ReadView 了,也就是说,查询的时候,创建 ReadView,然后三次查询,都使用下图这个 ReadView:
所以在这个事务结束之前,每次查询的结果,都只能拿到 quantity = 0 这条数据。
那之前我们说过,这个级别 InnoDB 实际上已经解决了幻读的问题,也是因为这个 ReadView 的原因,思考下,创建 ReadView 的时候,查询过程中就已经被限制返回为 NULL 了,所以没有 幻读 问题。
三.更新数据时undo_log的清理
那么 undo log 的日志会越堆积越多,总不能没有被清理的时候把。这个时间点就要把握在,接下来所有事务 都不需要 再访问这个 undo log 版本的时候,后台线程会清理掉。大概什么时候,就是 UPDATE 提交以后,后面的事务已经一致返回的是比当前这个 UPDATE 数据还要新的数据的时候,就已经可以清理掉了。
四.小小结
通过 版本并发控制管理MVCC 来隔离数据。